Quick Draw! Google

A fine 2016 Google ha messo on-line Quick, Draw! uno dei suoi esperimenti di intelligenza artificiale e machine learning. Il sito chiede alle persone di disegnare delle forme: un maiale, un tubo per annaffiare il prato, una padella, ecc... e in meno di 20 secondi, attraverso una rete neurale, il computer prova a indovinare cosa è stato disegnato.
Più di 15 milioni di persone hanno partecipato al gioco e, così facendo, Google è riuscita a raccogliere un dataset di più di 50 milioni di disegni che, qualche giorno fa, è stato rilasciato pubblicamente.
Il dataset si compone di 345 categorie e, oltre ai dati vettoriali delle immagini sono inclusi anche una serie di metadati.
L'obiettivo del rilascio di questi dati è:
We're sharing them here for developers, researchers, and artists to explore, study, and learn from.
Nel giro di poche ore sul mio feed twitter sono comparsi i primi esperimenti (i più interessanti sono quelli di @frauzufall che trovate qui) la maggior parte dei quali, però, generati con OpenFrameworks.
Non trovando nessuno che stesse utilizzando Processing, ho deciso di scrivere un piccolo programma in questo linguaggio per dare la possibilità a tutti di utilizzare questo dataset
Struttura dei dati
I file che si scaricano dal repository rilasciato da Google sono file di tipo .ndjson ovvero file con un oggetto di tipo JSON per ogni riga di file.
Ciascun oggetto è composto dai seguenti dati:
- key_id (integer): numero univoco che identifica il disegno
- word (string): la categoria che era stata richiesta
- recognized (boolean): se il disegno era stato riconosciuto (true) oppure no (false)
- timestamp (datetime): quando il disegno è stato creato
- countrycode (string): due lettere per identificare la nazione del giocatore
- drawing (string): un array JSON contenente i dati vettoriali del disegno
{
"key_id":"5891796615823360",
"word":"nose",
"countrycode":"AE",
"timestamp":"2017-03-01 20:41:36.70725 UTC",
"recognized":true,
"drawing":[[[129,128,129,129,130,130,131,132,132,133,133,133,133,...]]]
}
Per semplificarmi la vita, mi sono concentrato solo sull'ultimo tipo di dato: il mio obiettivo era caricare i dati del dataset e ridisegnare le forme con Processing.
L'array contenente i dati del disegno è a sua volta strutturato in questo modo:
[
[ // First stroke
[x0, x1, x2, x3, ...],
[y0, y1, y2, y3, ...],
[t0, t1, t2, t3, ...]
],
[ // Second stroke
[x0, x1, x2, x3, ...],
[y0, y1, y2, y3, ...],
[t0, t1, t2, t3, ...]
],
... // Additional strokes
]
Per fortuna la documentazione di Google è molto chiara: x e y sono le coordinate e t è il tempo trascorso in millisecondi dal primo punto.
Dati preprocessati
I dati contenuti nel dataset sono molti e, infatti, ciascun file pesa diverse centinaia di megabyte. Per fortuna il team di Google ha messo a disposizione anche dei file preprocessati: sono state rimosse le informazioni temporali e tutti i dati sono stati allineati e ridimensionali in un quadrato di 256x256 pixel.
I file .ndjson prepocessati sono disponibili a questo link e, come potete notare, la dimensione è notevolmente ridotta anche se si tratta, pur sempre, di almeno 40-50 megabyte per file.
Importare i dati in Processing
Primo problema: in Processing non esistono funzioni che ci permettono di lavorare su oggetti di tipo JSON differenti a meno che non siano inclusi in un array. All'inizio avevo, dunque, optato per modificare il file dei dati ma, grazie al suggerimento di un utente su Facebook, ho scoperto l'esistenza dell'oggetto BufferedReader che si usa per leggere un file una riga alla volta.
Una volta risolto questo inghippo, tutto è diventato più semplice: le linee restituite dall'oggetto sono di tipo String. Con la funzione parseJSONObject() ho convertito la stringa in un oggetto JSON.
Quick, Draw!
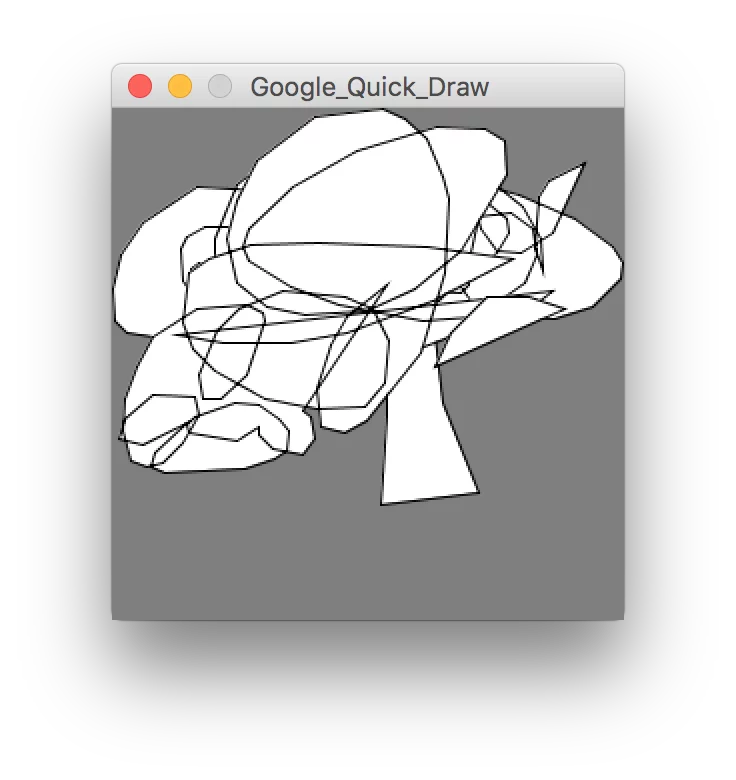 Vorrei conoscere chi ha disegnato questa "incudine"
Vorrei conoscere chi ha disegnato questa "incudine"
Avendo accesso all'oggetto JSON, l'unico passaggio da fare era estrarre dall'array drawing i dati x e y e assegnarli ai vertici di una forma per poterla disegnare a schermo.
Per farli ho usato un'insieme di funzioni di cui parleremo in futuro.
Per i più curiosi, il codice è disponibile su questo repository su GitHub.